Remember that this project exists for the benefit of our users, and that we wouldn’t keep doing this were it not for spreading the love to our users. This project exists because of your support and belief in us to keep going doing great things. We have always prioritized the endusers experience, and unlike others, we have never emburdened them with in-app ads, monetization SDKs or paywalled features, and we intend to continue to do so. If you’d like to show your support, consider donating to us. Check here in order to learn more. In addition to being able to support us on Patreon, there is now also the option to sponsor us on Github Sponsors! You can also help us out by buying some of our merch on our Teespring store!
Changelog
1.21.0
3DS: Fix unique IDs for newer cores
3DS: Enable TLS (SSL)
3DS: Fix UI freeze when threaded rendering is enabled
3DS: Fix crash on load content
3DS: Other minor fixes
APPLE: Enable Vulkan emulated mailbox
APPLE: Include b2 core in App Store builds
APPLE: CoreMIDI driver for IOS/MacOS
APPLE: CoreLocation driver for IOS/MacOS
AUTOCONF: Enable alternative display name in autoconfig files
AUTOCONF: Make autoconfig failure messages optional
AUDIO: Option to mute on rewind
AUDIO/PIPEWIRE: Fix app launch when pipewire service is stopped
AUDIO/PIPEWIRE: Fix speedup with threaded video mode
AUDIO/PIPEWIRE: Fix latency setting and microphone handling
AUDIO/PIPEWIRE: Pass the new rate to the audio driver
CAMERA: Add PipeWire camera driver
CAMERA: Add ffmpeg camera driver
CHEAT: Rewrite part of cheat_manager_load_cb_second_pass()
CHEEVOS: Include achievement state in netplay states
CHEEVOS: Fix crash when entering achievements in quick menu while client is not present
CHEEVOS: Restore cheevos_badges_enable for HAVE_GFX_WIDGETS builds
CLI: Allow –entryslot to fall back to normal states
CLOUDSYNC: Fix Windows path issues
CLOUDSYNC: Workaround for duplicated requests bug
CLOUDSYNC: Workaround for 301 redirects
CLOUDSYNC: Handle ignored directories properly
EMSCRIPTEN: Added new AudioWorklet driver, a fast callback-based audio driver
EMSCRIPTEN: Scale window to correct size
EMSCRIPTEN: Additional platform functions
EMSCRIPTEN: Add new default video context driver: emscriptenwebgl_ctx
EMSCRIPTEN: Add new audio driver: AudioWorklet
EMSCRIPTEN: Add new modernized web player which will eventually replace the existing one
EMSCRIPTEN/RWEBINPUT: Add touch input support
GAMECUBE: Fixes
GENERAL: Fix save state auto increment
GENERAL: Fix softpatching with periods/dots in the file name
GENERAL: Fix compilation with –enable-videocore
GENERAL: Allow asset directory redefinition and other directory overrides via environment variables
GENERAL: Allow override of player 1/2 input with machine learning models (needs recompilation and external library)
GENERAL: Fix performance counter option not remembered between sessions
GENERAL: Create security statement
GENERAL: Fix crash when core is not selected
GENERAL: Use core fps instead of screen refresh for calculating dropped frames
INPUT: Fix a crash when initializing illuminance sensor on Linux
INPUT: Analog-to-digital refactor, fixing behavior when analogs are assigned to keys
Jesse Talavera here again! You may remember me from my work on melonDS DS, McSoftServe, and assorted improvements to RetroArch like microphones and XDelta softpatching. I’ve secretly been developing something brand-new that I’m itching to share with you.
Although RetroArch was designed for retro game emulation, every now and then something comes along that breaks out of that mold. To that end I’d like to introduce ROM Cleaner, a unique utility core that’ll help keep your digital ROM backups running as reliably as the day you dumped them.
As retro gamers, we’re no strangers to data degradation’s many forms. Flash memory loses its charge, tapes decompose, discs rot. But keeping your media in a clean environment will help protect it from time’s relentless siege, and digital backups are no exception! If you find that one of your ROMs is beginning to degrade and won’t boot anymore, simply run it through ROM Cleaner to rid it of the dust that’s accumulated over the years. All you need is a microphone and a set of lungs, and you’ll never have to worry about dirt building up in your digital collection again.
Our mission is to keep yesterday’s games playable and fun for generations, and ROM Cleaner is my latest contribution to that effort. You can get it from RetroArch’s core downloader on supported platforms today. I hope you’ll get just as much use out of it as I am!
Has the same USB ID so that you do not need to reconfigure your software
Has the same mapping, and code logic just faster with greater controller support
Compatible with 4-Play/GP Cables
Advantages over the 4-Play.
Xinput and HID support
Fixed USB 1mS Poll rate
USB 2.0 High Speed
True Force Feedback Ready
No Combo (rumble) fix needed
Retro Arch
The 4-Play Advanced is a drop in replacement for the existing 4-Play for any Retro Arch user. The USB ID and mappings follows the 3.0 layout. As long as you have the mappings loaded, it will work the same way. The 4-Play Advanced has a USB poll rate of 1ms and now uses a hardware based USB chip for a much better force feedback experience. In addition, you can now change to xinput mode instead of HID. The mapping and layout for Xinput would follow the xbox 360 gamepads. This mode uses its own USB ID, so mappings are required but should follow 360 gamepads
We have a brand new PlayStation2 core, LRPS2. It’s a heavily modified version of PCSX2 custom made for the Libretro API, and it currently runs on Windows, macOS and Linux.
The core code is modern and up-to-date unlike the old core and it no longer suffers from the serious drawbacks the older core had.
It supports nearly all the rendering backends for the GSdx renderer: Vulkan on Windows/macOS/Linux, Direct3D 11 and 12 on Windows, and OpenGL on Windows/Linux.
For those interested, you can also read our compendium article here posted earlier today.
All the screenshots below were taken with the paraLLEl-GS renderer and the following settings: 16x SSAA, paraLLEl experimental high-res scanout turned on. Shader preset used is: presets/fsr/fsr-aa-lv2-bspline-4taps.slangp.
How to set it up/use it
On platforms where the core is available (that is, Windows, Linux, and MacOS; it is NOT available for Android or iOS), go to the online updater and scroll down to ‘Update Core Info Files.’ This will ensure that the core shows up properly under the correct name in the menu. Then, head over to the online updater’s ‘Core Downloader’ and scroll down to ‘Sony – Playstation 2 (LRPS)’ to download the actual core. Next, go to the online updater’s ‘Core System Files Downloader’ and get the LRPS2.zip bundle. This bundle will automatically create the ‘pcsx2’ directory in your ‘system’ directory and put the GameIndex.yaml–which includes the various per-game hacks/settings the core and gsDx renderer use for compatibility–inside. It will also create the ‘bios’ directory, inside which you will need to place your PS2 BIOS set. Once that’s done, you’re ready to scan and/or load your games, which can be in a variety of formats, including CHD, but make sure they are not in *.7z, *.rar, *.zip, etc. compressed archives.
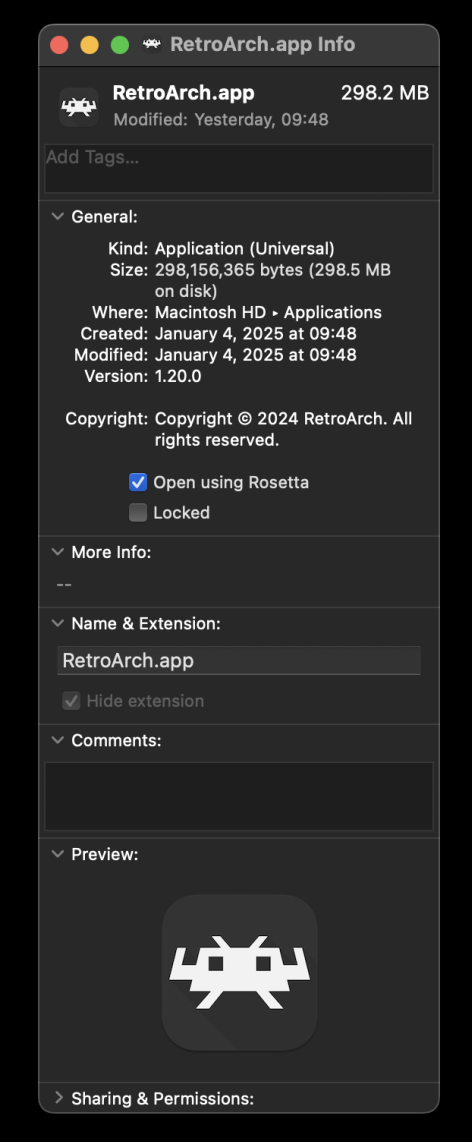
How to use it on macOS (Apple Silicon)
On macOS running on Apple Silicon, you must use Rosetta. To run in Rosetta, exit RetroArch, and show it in Finder. Right-click on it and choose “Get Info” from the menu. In the Info screen is a checkbox to “Open using Rosetta”; make sure it is checked.
Once it’s running in Rosetta, you will see the LRPS2 core in the Core Downloader.
Explanation of core options:
System
Fast Boot
Skips BIOS startup screen and boots straight to the game. Disable this if you want to access the PS2 system settings or access the Memory Card manager.
Fast CD/DVD Access
Fast CD/DVD access/seek times. A small handful of games will have compatibility problems with this enabled (such as Klonoa 2).
Enable Cheats
Enable cheat files to be read from the ‘cheats’ directory in the system folder. This works the same as mainline PCSX2, it tries to read a cheatfile of the game’s CRC hash followed by the extension ‘.pnach’.
Language Unlock hint – Looks inside LRPS2’s internal database to find language unlocks or override patches for the game. Some examples:
Final Fantasy X International – By enabling this, you can force the game to set the Language to ‘English’ by default. The International version is a Japanese/Asian version of the game that has both Japanese and English language options, but defaults to Japanese by default. It’s basically an undubbed version of the game.
For other games it simply unlocks more language options that are found in the game’s code but never enabled.
Video
Renderer – Select the renderer to use. Restart for the changes to take effect.
Auto – Will use the video driver set in the Libretro frontend (i.e. RetroArch). So if RetroArch is set to Direct3D12, it will try to use the Direct3D12 GSdx renderer. If you set it to Vulkan, it will try to use the Vulkan GSdx renderer.
paraLLEl-GS – Select this to use the new LLE renderer by Themaister. For this to work, you need to make sure your video driver is set to Vulkan in the Libretro frontend (i.e. RetroArch).
Software – Select this to use the software renderer. WARNING: Don’t use this in combination with ‘Vulkan’ or the core will crash at startup. To get out of this, set RetroArch’s video driver to ‘OpenGL’, ‘Direct3D11’ or ‘Direct3D12’, and then make sure to set the ‘Renderer’ to something else.
Deinterlacing – Select a deinterlacing method. Use ‘Automatic’ if unsure what to pick. You can set this to ‘Disabled’ when you’re using a progressive scan mode and absolutely no interlaced images are being used.
No interlacing hint – Looks inside LRPS2’s internal database to find a no-interlacing/progressive scan patch for the game.
Some games have internal progressive scan options. These can usually be enabled by press and holding Cross + Triangle at the start of a game. If the game supports progressive scan, it will then ask if you want to enable this mode. The nointerlacing hint will try to auto-enable this progressive scan mode where possible so you don’t have to manually set it. Not all the codes have been found for every game though so don’t assume this will always be set.
Some games use field rendering (interlaced mode) or are full frame rendering games but still look rather bad in high-res scan out. However, there are fancy patches for some games to disable final output of the downsampled front buffer and instead point the front buffer pointer directly to the higher-resolution back buffer instead. The nointerlacing database has patches like this for games like the Snowblind Engine v2 games (thanks to Agrippa for discovering this) and Tekken Tag Tournament.
Widescreen hint – Looks inside LRPS2’s internal database to find a widescreen patch for the game.
Some games have a built-in widescreen mode. The Widescreen hint tries to enable these modes when possible so the user doesn’t have to manually do it. The list of games that we do this for right now are small.
Most PS2 games implement widescreen modes using Vert-, which means you lose screen real estate in widescreen mode instead of actually gaining it (Jak and Daxter, Ratchet & Clank). Most of the widescreen patches that are in the database try to adhere to Hor+ and in some cases override the game’s original Vert- implementation.
If you set it to 16:10 / 21:9 / 32:9 and it cannot find a patch for that aspect ratio but there is a 16:9 patch available, it will instead apply the 16:9 patch instead as a fallback.
When a widescreen patch is not found for the game inside the database, it will default to ‘stretched’ mode, where it stretches the 4:3 image across a 16:9 aspect ratio. This is of course the worst-case scenario, and when you find the image to be stretched like this, we recommend you turn the Widescreen hint off for that game.
PCRTC Anti-Blur – Disable this for the most accurate output image. Enabling this will attempt to deblur the image. Most noticeable on software renderer and paraLLEl.
Disable Interlace Offset – Debug option. Not recommended to be used by endusers.
The following settings only apply to the gsDX renderer (so NOT paraLLEl-GS)
Video – GSdx
Internal Resolution – Restart for the changes to take effect. Just like it says.
Dithering – You can combat the dithering a bit with these settings.
Blending Accuracy – The higher you set this, the more demands it will place on your GPU. Some games might get away with basic blending while others recommend this to be set far higher. Note that paraLLEl GS always defaults to the highest possible blending accuracy, unlike GSdx. No shortcuts on paraLLEl GS!
Manual Hardware Rendering Fixes – GSdx
Enable Manual Hardware Renderer Fixes – This will disable all the GSdx game-specific settings from the GameIndex.yaml database. Unless you know what you are doing, it is NOT recommend to turn this ON. Note that for paraLLel-GS this is entirely irrelevant, it uses no per-game specific rendering fixes at all and is not reliant on GameIndex.yaml at all.
Emulation
EE Cycle Rate – Overclock or downclock the Emotion Engine CPU (the main PS2 CPU). 130% cycle rate corresponds to cyclerate 1, 180% 2, 300% 2. Depending on the internal ‘uncapped framerate’ patch found, you might need to slightly apply some overclocking here to make sure the game can maintain a consistent framerate.
Game Enhancements hint – Looks inside LRPS2’s internal database to find game enhancement patches for the game. These enhancements include but are not limited to:
QoL Skip cutscenes – Being able to skip a FMV scene by pressing a button (usually X). Some games like God of War 2 normally don’t let you skip cutscenes.
Draw distance/NPCs onscreen. The Dynasty Warriors/Shin Mousou games have various game enhancements patches implemented so that the fog is drawn out further into the distance and more of the scenery can be seen. These games would normally go really aggressive on the distance fog. The patches also increase the maximum amount of NPCs rendered onscreen. Some racing games, like Sega Rally 2006, have draw distance enhancement patches enabled also.
LOD enhancements. Some games use Level of Detail for meshes, like Gran Turismo 4. When we have patches to disable these, we turn them on here. It looks better in high-resolution mode when you don’t see models popping from a low-quality version of the model to a high-quality version depending on their distance from the camera/player.
Uncapped Framerate hint – Looks inside LRPS2’s internal database to find a patch that uncaps the frame rate (or stabilizes it). NOTE: Use this together with the ‘CPU Cycle Rate’ option, most games can run fine at 130% CPU Cycle Rate uncapped while others might need 180% or even 300%.
SSX 3 uses this hint for a ‘no frame skip’ option. The PS2 version of the game normally skips frames on certain demanding scenes of the game. With the emulator we don’t really need to do this so we can just stub out the frame skipping code and enjoy a full 60Hz/60fps everywhere. This in some respects makes this the best version of the game to play now (the PS2 version has enhanced bloom/lighting effects not found on Xbox OG).
Burnout 3/Revenge normally have 30fps menus and crash replays. Enabling this makes them run at 60Hz/60fps (NTSC) or 50Hz/50fps (PAL).
Input
Port 1: Analog Sensitivity: Set this higher or lower if the deadzone on your controller’s analog stick behaves weird.
Port 2: Analog Sensitivity: Same but for port 2.
ParaLLEl-GS – Reimplementing the Graphics Synthesizer in compute
By far the star of the show is paraLLEl-GS. Just like paraLLEl-RDP before it, this is a brand new renderer made by Themaister written entirely as a compute program. It’s written exclusively for the Vulkan graphics API.
For a detailed breakdown on this project, read Themaister’s blog article here (it’s several months old by now though).
The goal and aim of this renderer is to be as accurate as the software renderer, but with additional graphical enhancements. SSAA is by far the biggest standout feature of this renderer. When set to 16x SSAA and high-res scan out enabled, it can eliminate all the shimmering and jaggies on 3D geometry and textures.
With high-res scan out enabled, it is possible to double the resolution. Combine this with SSAA and the final output image quality can often exceed gsDX rendering at much higher internal resolutions. And unlike gsDX, almost no hacks have to be enabled/disabled on a game-specific basis for the game.
Explanation of ParaLLEl-GS core options:
paraLLEl Supersampling – Apply supersampled anti-aliasing (SSAA). Unlike straight upscaling, supersampling retains a coherent visual look where 3D elements have similar resolution as UI elements. For high-res scanout to work, you need at least ‘4x SSAA ordered’ (or higher). Setting this to ‘Native’ disables super sampling.
paraLLEl experimental High-res scan out – Allows upscaling with paraLLEl. Some might require patches on top. Requires Supersampling to be set to at least ‘4x SSAA ordered’ (or higher) for it to work. The higher the SSAA mode, the better this will look, but the more demanding it will be on your GPU
paraLLEl experimental SSAA texture – Feedback higher resolution textures. May help high-res scanout image quality. Highly experimental and may cause rendering glitches.
paraLLEl experimental sharp backbuffer – Attempts to workaround games that add extra blit passes before scanning out. May lead to better image quality in certain games which do this. This option can be hit and miss for some games. For some games like ‘Mahou no Pumpkin’ it will make the output image very sharp and crisp, while with other games it makes either no difference or has some issue. Experiment with this option.
Force LOD Texture 0 – Disable this for traditional hardware mipmapping. Enabling this will bypass mipmapping and always use texture LOD0 instead. The result is better image quality. Only a small handful of games have graphics rendering issues with this enabled.
Frequently Asked Questions (FAQ)
Q: I get a black screen but can hear audio.
A: If you’re using the D3D11 video driver (which is the default video driver on Windows), some users get a black screen instead of video. Switch your video driver to D3D12 (either globally or just for this core via core override) and then reopen the core and content.
Q: ParaLLEl-GS is very slow on my Intel integrated graphics.
A: Yes, unfortunately, Intel IGPs just aren’t very good at compute shaders. Even relatively recent models fail to run at full speed. The software renderer and gsDx renderer are still the best options in this case. For the record, Intel’s new discrete GPU models should handle it just fine.
Q: The software renderer crashes when I use the Vulkan video driver.
A: Yes, this is known but we don’t know why yet. Until we figure it out, you’ll need to swith to the “glcore” driver in Linux or one of the D3D drivers in Windows to use the software renderer reliably.
Q: What about analog face buttons??
A: We’re working on this, but thankfully it’s only usable in a few games and all games are still playable/complete-able without it.
Q: How can I tell what internal patches are being applied on a per-game basis?
A: Currently this is a bit inconvenient. You need to enable Logging in RetroArch and then look at the log output to see if any of the hints (Game Enhancements, Language Unlock, No interlacing, Widescreen) led to patches being applied by LRPS2. Far from all games have been implemented inside the internal database but we intend for this database to grow quite large.
Q: I’m not seeing LRPS2 in the core list.
A: The core is probably not available for your platform. It is available for Windows, Linux (x86_64), and MacOS. It is NOT available for Android or iOS, nor for ARM Linux. If you’re sure it should be there for your platform and you’re still not seeing it, try updating your core info files via the online updater.
Q: How can I improve frame pacing in the core?
A: Try the option ‘Sync to Exact Content Framerate (Settings -> Video -> Synchronization). If you’re using a VRR display, turn VSync Off in RetroArch and make sure Vsync is enabled in the Nvidia driver control panel (if using an nVidia GPU). Some games like Fighting Vipers and Sega Rally 1995 will not behave well with ‘Sync to Exact Content Framerate’ enabled though, so your mileage may vary. Experiment and find out what works best for you.
Remember that this project exists for the benefit of our users, and that we wouldn’t keep doing this were it not for spreading the love to our users. This project exists because of your support and belief in us to keep going doing great things. We have always prioritized the endusers experience, and unlike others, we have never emburdened them with in-app ads, monetization SDKs or paywalled features, and we intend to continue to do so. If you’d like to show your support, consider donating to us. Check here in order to learn more. In addition to being able to support us on Patreon, there is now also the option to sponsor us on Github Sponsors! You can also help us out by buying some of our merch on our Teespring store!
Shader subframes
We’ve added a new CRT beam simulation shader from Mark Rejhon of BlurBusters (blurbusters.com) and Timothy Lottes (creator of the original FXAA shader and the crt-lottes shaders). It leverages RetroArch’s recently added “subframe” shader capabilities to significantly improve motion clarity on modern displays without the typical drawbacks associated with black-frame insertion (BFI) implementations, such as reduced brightness, dulled colors, and risk of image persistence (the non-permanent-but-still-scary cousin of CRT/OLED “burn in”) that occurs on many common LCD panel types.
For more information, read our separate article here.
Illuminance sensor support for Linux
Jesse Talavera here again! I’ve been working on something fun: illuminance sensor support for Linux! Now you can play Boktai with real light, just as intended. Check out this clip of Lunar Knights running on my Steam Deck as I adjust the lights:
☀ Now we’re cooking with sunlight! ☀ melonDS DS’s next update will include solar sensor support (among other things), so look forward to that! Also coming soon after 1.20.0 — camera support for more platforms!
Changelog
1.20.0
AUDIO: Fix audio handling in case of RARCH_NETPLAY_CTL_USE_CORE_PACKET_INTERFACE
AUDIO: Include missing audio filters on some platforms
AUDIO/PIPEWIRE: Add PipeWire audio driver
AUDIO/PIPEWIRE: Add PipeWire microphone driver
APPLE: Hide threaded video setting
APPLE: Use mfi joypad driver by default
APPLE: Include holani, noods, mrboom, yabause, bsnes-jg core in App Store builds
CHEEVOS: Add rarity and points to achievement unlock widget
CHEEVOS: Add rank to leaderboard submission notification
CHEEVOS: Update to rcheevos 11.5
CHEEVOS: Update to rcheevos 11.6
CHEEVOS: Show rcheevos game image in Discord rich presence
CHEEVOS: Use translated strings for achievement messages
CLOUDSYNC: Allow saves and configs to be synced optionally
CLOUDSYNC: Add iCloud cloud sync driver
CLOUDSYNC: Speed up by upload/download in parallel
CLOUDSYNC: Allow thumbnails and system dir to be synced optionally
CLOUDSYNC: Enable CloudSync on Android (non-SSL)
CLOUDSYNC: Add more logs in failure situations
CLOUDSYNC: Fixes for reauthentication and parallel sync
CLOUDSYNC: Fixes for file resurrection
CLOUDSYNC: Enable CloudSync on Windows
CRT/SWITCHRES: Update switchres to 2.2.1
GENERAL: Support for mbedtls v3
GENERAL: Automatic Frame Delay refactor
GENERAL: Remove Frame Rest, obsoleted by Frame Delay refactor
GENERAL: Wrap around auto increment save state indexes when amount of states is limited
GENERAL: Enable CHD hashing for Switch and DOS
GENERAL: Enable auto save state when new content is loaded
GENERAL: Improve Preemptive Frames when pointing device is used
GENERAL: Fix building with menu disabled
HAIKU: Restore Haiku build
INPUT: Allow to select a preferred/reserved device for each player
INPUT: Enable Caps, Num, Scroll Lock modifiers on multiple platforms
INPUT: Autoconfig extension with alternative name/vid/pid
INPUT: Fix autoconfig profile saving when device is not in the default port
INPUT: Change classic turbo mode to work independently of which key was pressed first
INPUT: Pointer and lightgun handling sanitization on Windows and Linux desktop platforms. These input drivers will now report edge and offscreen positions in a harmonized way, and will not return 0 instead.
INPUT/DINPUT: Fix detection of quick shift key presses
INPUT/HID: Fix crash on macOS when disconnecting the controller a second time
INPUT/LINUX: Add illuminance sensor support to the linuxraw, sdl2, udev, and x11 input drivers
INPUT/Remaps: Sort and apply remaps based on the specific connected controller
INPUT/UDEV: Enable mouse buttons 4 and 5
INPUT/WAYLAND: Enable horizontal scroll and mouse buttons 4 and 5
INPUT/WAYLAND: Simulate lightgun input for cores
INPUT/WAYLAND: Support for cursor-shape-v1 and content-type-v1 protocol
INPUT/X11: Enable mouse buttons 4 and 5
iOS: Enable vibration by default
iOS: Better handling of physical mice/magic keyboard trackpad
iOS: Mouse grab fixes
iOS: Fix mouse cursor movement when button is held down
iOS: Fix microphone support request and entitlement
iOS: Enable compilation back to iOS 12
iOS: Fix OpenGL ES context usage on iOS 9
iOS/TVOS: Add Opera to App Store build
iOS/TVOS: Bring NEON defines in line with ARM64
iOS/TVOS: Flush save files on backgrounding
LIBRETRO: Support RETRO_ENVIRONMENT_GET_FILE_BROWSER_START_DIRECTORY
LIBRETRO: Support “/” as a file extension for loading a directory as content
FFMPEG: Fix crash when playing back a file with 96 kHz audio
MACOS: New display server, including support for ProMotion 120Hz V-Sync
MACOS: Create App Store build
MACOS: Generate key up events for command keys
MIDI: Fix long messages (SysEx) in WinMM driver
MIDI: Fix lingering notes on close in Alsa driver
MENU: Support local thumbnails in other image formats than png (jpg/jpeg, bmp, tga)
MENU: Delete also savestate thumbnails when savestates are garbage collected
MENU: Option to disable analog stick menu navigation
MENU: Fix pause toggle to not clear fast forward state
MENU: Fix search playlist index in XMB/Ozone
MENU: Fix renamed entry display
MENU: Filter unknown extensions also inside zip files
MENU: Add icons for present / missing firmware on core info page
MENU: Ignore other hotkeys when menu toggle is pressed
MENU: Fix menu jumping when using L3+R3 combo
MENU: System Information now only shows features relevant for the platform
MENU/GLUI: Make Show Sublabels options effective
MENU/GLUI: Icon fixes
MENU/XMB: Allow playlist icons to be individually customized, by looking for images in Named_Logos
MENU/OZONE: Add Selenium theme for Ozone
MENU/OZONE: Touchscreen improvements
MENU/OZONE: Add a touch-sensitive Resume button in the lower right corner
NETPLAY: Add East Asian relay server
OVERLAY: Add option to load overlay based on system name
PS2: Fix several broken cores depending on pthread
QT: Enable building with Qt6
QT: Fix input panel
RECORDING: New WAV recording driver (audio only)
REMOTE RETROPAD: Add gyro/acceleration/light sensor test screen
REMOTE RETROPAD: Add pointer test screen
REPLAY: Replay format extended to support external tools
TVOS: Support bluetooth keyboards on tvOS
TVOS: Fixes to run correctly on TVOS13
TVOS: Better handling of Siri remote
TVOS: WebDAV server for adding files more easily
TVOS: Add Settings.app option to reset retroarch.cfg
TVOS: Bring minimum tvos version down to 13.0
VIDEO: Show and use exact refresh rate (3 decimals) and interlace/doublestrike where available
VIDEO: Allow setting viewport bias to offset viewport horizontally/vertically
VIDEO: Support viewport bias also with integer overscale and custom aspect ratios
VIDEO: Use shader path from CLI for shader cycling
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
_ga
ID used to identify users
2 years
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gat
Used to monitor number of Google Analytics server requests when using Google Tag Manager
1 minute
Marketing cookies are used to follow visitors to websites. The intention is to show ads that are relevant and engaging to the individual user.
A video-sharing platform for users to upload, view, and share videos across various genres and topics.
Registers a unique ID on mobile devices to enable tracking based on geographical GPS location.
1 day
VISITOR_INFO1_LIVE
Tries to estimate the users' bandwidth on pages with integrated YouTube videos. Also used for marketing
179 days
PREF
This cookie stores your preferences and other information, in particular preferred language, how many search results you wish to be shown on your page, and whether or not you wish to have Google’s SafeSearch filter turned on.
10 years from set/ update
YSC
Registers a unique ID to keep statistics of what videos from YouTube the user has seen.
Session
DEVICE_INFO
Used to detect if the visitor has accepted the marketing category in the cookie banner. This cookie is necessary for GDPR-compliance of the website.
179 days
LOGIN_INFO
This cookie is used to play YouTube videos embedded on the website.
2 years
VISITOR_PRIVACY_METADATA
Youtube visitor privacy metadata cookie
180 days
You can find more information in our Cookie Policy and .