We are excited to introduce a new shader that significantly improves motion clarity on modern displays, without the typical drawbacks associated with black-frame insertion (BFI) implementations. This shader is the work of Mark Rejhon from BlurBusters (blurbusters.com) and Timothy Lottes (creator of the original FXAA shader and the crt-lottes shaders). It leverages RetroArch’s recently added “subframe” shader capabilities, enabling it to operate at multiples of the standard content framerate.
NOTE: Make sure you use RetroArch 1.20.0 or a more recent version (any nightly will do). Previous versions do not support the Shader Sub-frames feature that this shader relies on.
Acronyms used: BFI (Black-Frame insertion), FXAA (Fast Approximate Anti Aliasing)
If you have a high-refresh-rate monitor (120 Hz or higher) and want to try it in RetroArch, follow these steps:
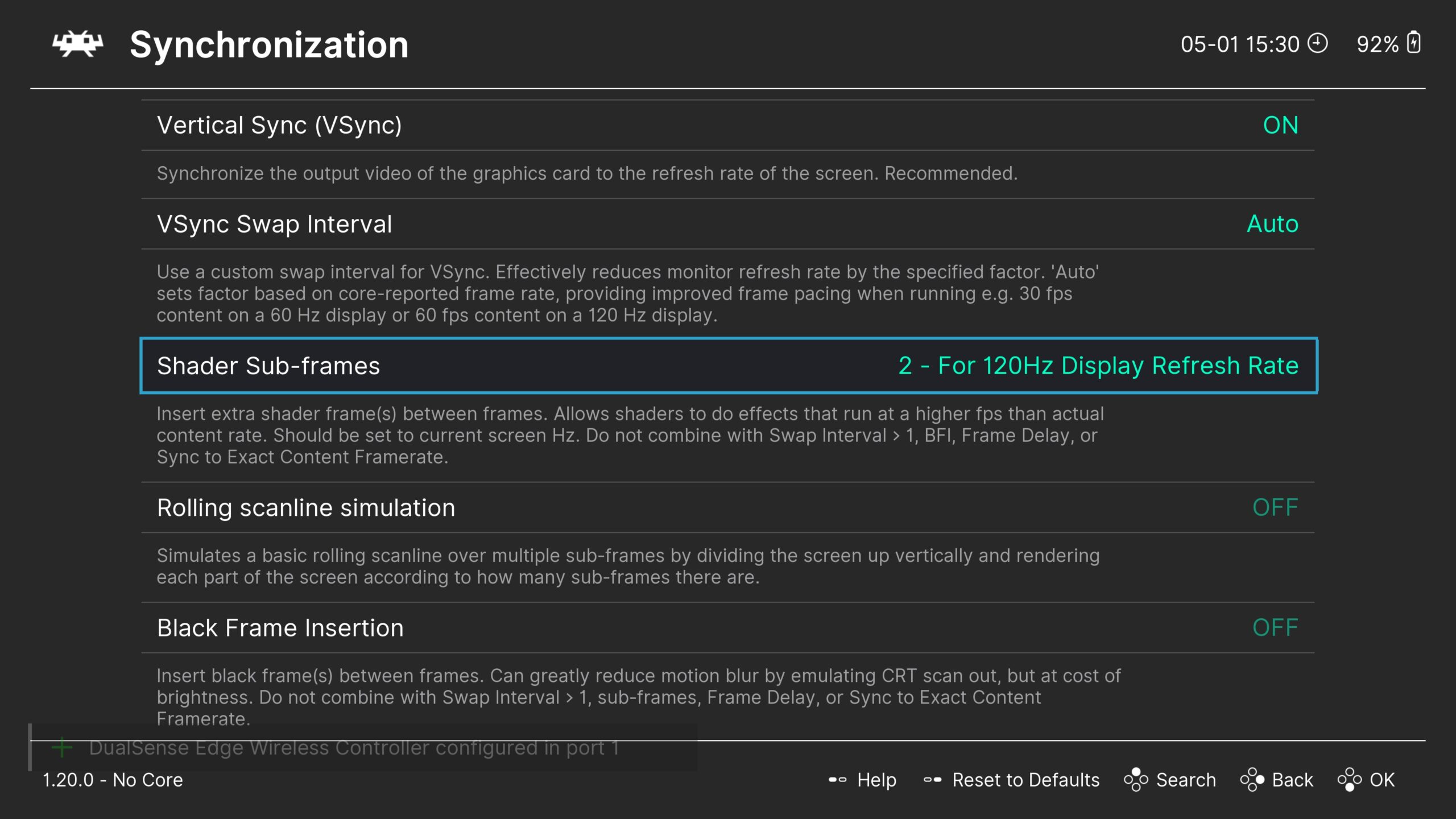
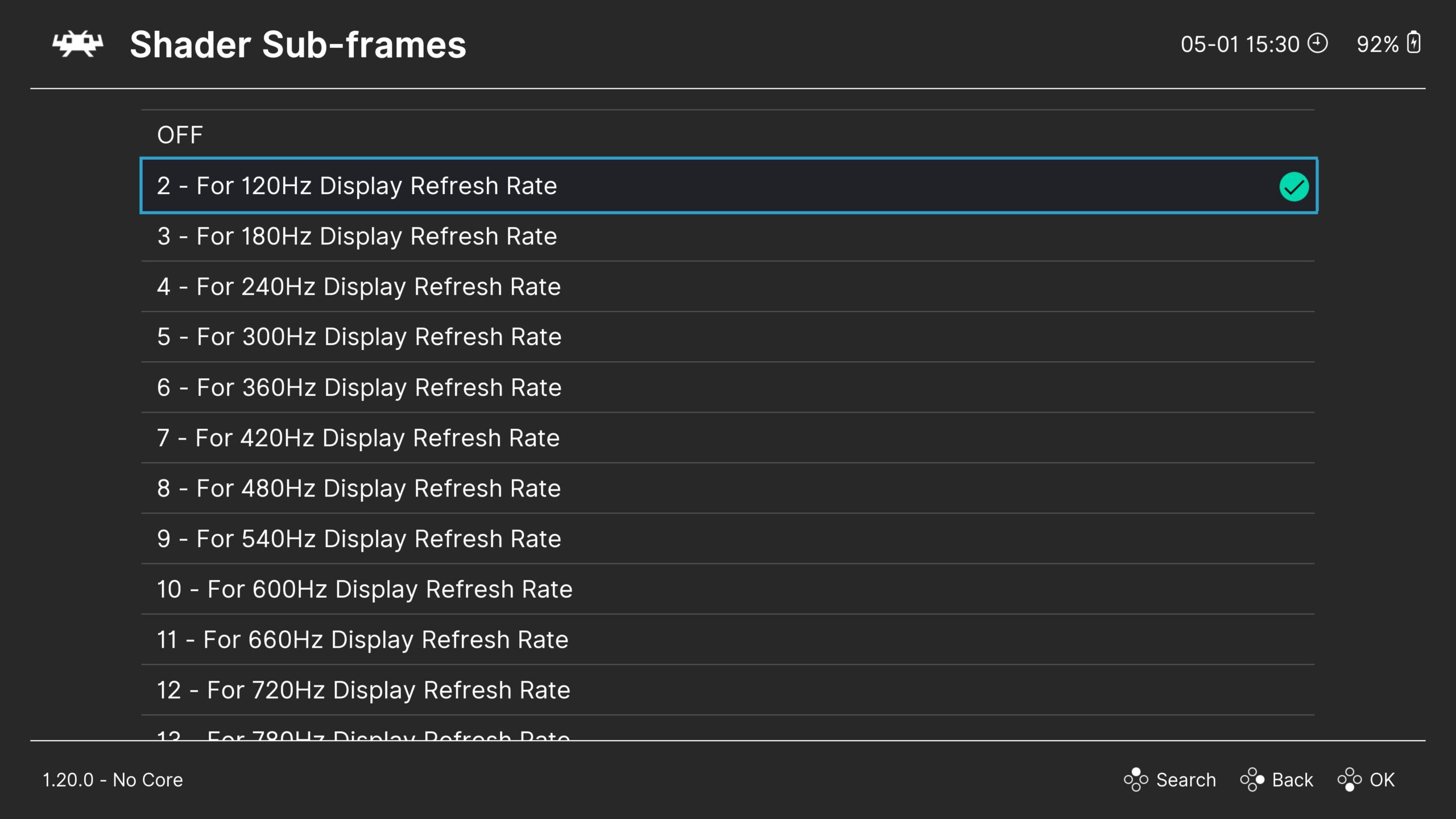
Go to Settings > Video > Synchronization and enable the “Shader Sub-frames” option that matches your monitor’s refresh rate.
Do not adjust the “Rolling Scanline Simulation” option, as it is unrelated.
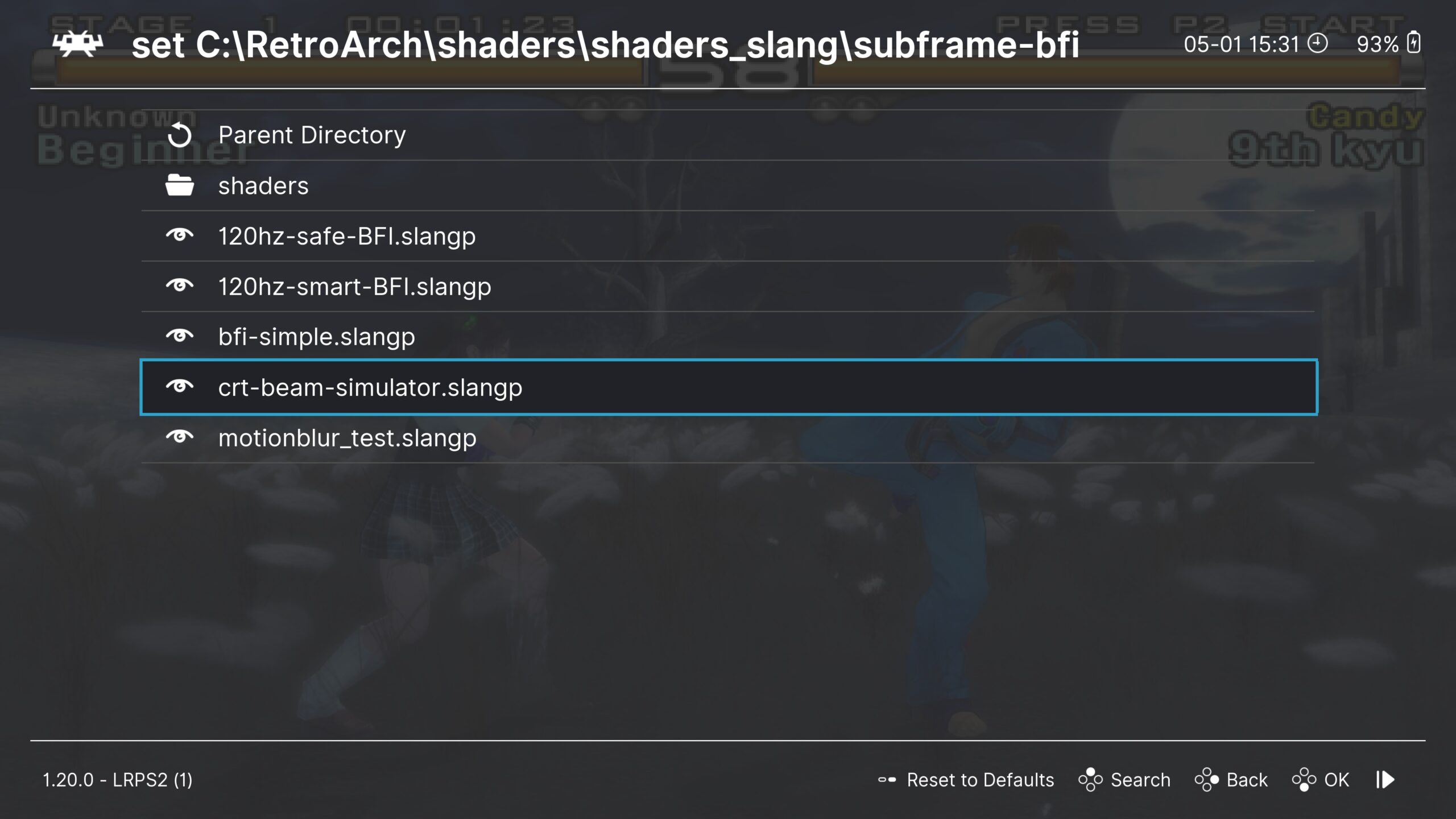
Load your desired core and content, then open the quick menu. Scroll down to Shaders and select Load Preset.
You can find the shader in the subframe-bfi directory, named “crt-beam-simulator.slangp.
If you’d like to combine this shader with others (e.g., your favorite CRT shader), you can usually prepend it to other presets without issue.
You can also select any of the pre-made presets that use the CRT beamracing shader. You can find these under shaders_slang/presets/crt-beam-simulator.
Once it’s up and running, the shader will need some tuning based on your specific display. It includes runtime parameters that allow you to adjust the gamma to achieve a neutral image (i.e., eliminating any unusual dark lines) and fine-tune the trade-off between brightness and motion clarity. For 120 Hz monitors (2 subframes), a value of ~0.5 works well, while ~0.7 is ideal for 240 Hz monitors (4 subframes).
Some of the key advantages of this shader over conventional BFI include:
Less flicker: The shader is much smoother and more forgiving of occasional frame drops.
Works with arbitrary refresh rates: RetroArch’s subframe feature is limited to integer values, but the shader automatically adjusts to match your subframe setting.
Prevents image persistence: It includes a small offset to cycle timing to prevent image persistence (often mistakenly called “burn-in”) on common IPS LCD panels. This issue is not permanent, like CRT burn-in, but can still be concerning.
Not all flat-panel monitors are at risk of image persistence, which is caused by voltage accumulation in the panel caused by the on/off flickering. OLED panels, for example, are unaffected, as are monitors running at odd integer multiples of 60 Hz, such as 180 Hz. If you’re using one of these displays, we’ve included a runtime parameter to disable the cycle timing offset, which stops the simulated raster line from rolling up the screen. There is also a parameter to adjust the position of the raster line, so you can place it in the least obtrusive spot for your setup.
If you encounter any issues with the shader, Mr. Rejhon has an FAQ and troubleshooting guide available on his GitHub repository: https://github.com/blurbusters/crt-beam-simulator/issues/4. You can also seek help through our usual support channels (Discord, Reddit, or the Libretro forums).
See also this video from a person quite knowledgeable in display technologies.
The PlayStation2 is a system designed almost entirely from the ground up for use with CRT TVs. Like any other game console built around analog video output, it is not designed around pixels or resolution, but scanlines and timing. Yes, there is a way to attach a VGA monitor for the official PS2 Linux toolkit so there are some VESA display modes as well, but this is more of an afterthought, and almost no real commercial game used this.
Acronyms used in this article: PS2 (PlayStation2), CRT (Cathode Ray Tube, old TVs that were replaced by HDTVs), GS (Graphics Synthesizer, the PS2’s GPU), PAL (European television signal for CRT TVs), NTSC (American television signal for CRT TVs in America/Japan), CRTC (Cathode Ray Tube Controller, the PS2 GPU has this), EDTV (Enhanced Definition TV or Extended Definition TV, an SDTV that supported progressive scan display modes), VU0/VU1 (Vector Unit 0/Vector Unit 1, two SIMD coprocessors of the PS2)
Sticking locked to 60fps to avoid bad image quality
The PlayStation2’s 4MB embedded VRAM for the Graphics Synthesizer (its GPU) was usually not big enough to hold a full 640×480 framebuffer (or something even bigger). Sony would insist developers not think of it as VRAM but rather a scratchpad, but there’s still only so much you can do with 4MB for render targets.
However, the bandwidth for the GS was unmatched, things like alpha blending, multipasses and framebuffer copies which are expensive on most other GPUs was nearly free on the PS2. In fact, many games like Driv3r abuse some of the GS’ strengths in ways that would bring any other GPU down to its knees. Thanks to its fully programmable geometry pipeline because of the two vector units (VU0 and VU1), the PS2 had hardware features like mesh shaders that we have only started to see being introduced on hardware like the Geforce RTX 20 series almost 18 years later. But we digress.
Developers were almost incentivized by the hardware to make sure their games maintained a solid 60Hz/60fps on NTSC (or 50Hz/50fps on PAL). How did Sony do this? It was perhaps not an intentional initiative but the end result was the same. For one, early versions of the SDK only supported interlaced scanline modes which required 60Hz to get 640×448. Later on, game developers had the option of either using frame mode (full frames) or field rendered mode (interlaced frames).
Field rendering being interlaced means the memory requirements per frame could be halved because the frame is output at 640×240 or even as low as 512×224. This was important because like we said before, the PS2’s GPU only had 4MB of embedded DRAM to work with, and you had to store your framebuffers there. A further benefit is the time needed to render the final output image is also reduced. So to many developers it seemed like field rendering mode was the way to go if you wanted to make a fast performing game on the PS2. So where is the catch? Here comes the big caveat and why PS2 games rarely skip a beat and try to ensure a perfectly locked 60fps. If you miss a frame and the previous one has to be displayed twice, you will see the whole image shift position Y by 1 line. It was therefore imperative to ensure this did NOT happen. So what most games would try to do is instead internally slow down the game by skipping frames when the game was in danger of not maintaining its 60fps target (like SSX 3) but continue to aim at a 60Hz/60fps target.
The other option was frame mode, rendering full frames. Render times obviously go up compared to field rendered mode because you’re rendering full fat frames (640×448 or 512×448), and therefore it might be harder to hit a consistent 60fps vs. field rendering mode. However, the system is more forgiving when you don’t render a new frame in time. The screen would just end up showing the second field from the previous frame.
So, to recap, if the game could maintain a consistently frame paced 60fps for a game, field rendering mode (i.e. interlaced mode) would look as expected, your CRT would blend the half frames and make it look like a full frame. The average enduser would be none the wiser about all the internal dealings of how a CRT assembles and finally outputs a picture, and you have the big advantage that this mode is faster than frame mode and therefore it’s easier to aim for a high framerate like 60fps. If the frame rate would be all over the place, it would lead to a bad picture like discussed in the earlier paragraphs, therefore it was on the developer to make sure you either slow the game internally down or you make sure it runs at a rock solid framerate.
Field rendering being a viable and fast option like this for PS2 as long as you could ensure 60fps/60Hz meant CRT saved the day and PS2 could get away with its generally unimpressive display resolutions.
It has not gone unnoticed by many that PlayStation2 has by far the largest amount of 60fps/60Hz games available (especially on launch day). Turns out there was a technical reason behind this that forced developer’s hand as much as it was developers really wanting to push themselves to the limit.
So if you ever wondered why PS2 games seem to so rarely miss their frametime targets while framerates jump all over the place on other consoles (even Xbox OG and GameCube, its two competitors from that generation), now you know.
We remember at the time PS2 launch games drawing heavy criticism at launch for jagged edges ( colloquially referred to as ‘jaggies’) and the lack of anti-aliasing, especially compared to the Dreamcast. What compounded this problem was that many game magazines and journalists could only do single frame capture. So when they took screenshots or pictures, they would only get half the fields in their pictures. So you’d get bad screenshots in magazines with only the odd or even lines being shown, leading to PS2 games looking much more jaggy in print than they actually did on a real screen. In reality the problem was not so bad, but the lower output resolution to fit in GS eDRAM probably did not help with the misunderstandings and misconceptions.
Widescreen, CRTs and the PS2
Let’s discuss widescreen display modes now and their use on CRT TVs. While a few PlayStation1 games had been adventurous and started implementing widescreen modes, it could be safely assumed that up until now the vast majority of console games were all designed around 4:3 aspect ratios. However, this was soon about to change, thanks in no small part to the PS2. The PS2 doubled as a DVD player and the term ‘anamorphic widescreen’ started being thrown around a lot. Widescreen 16:9 CRT TVs started becoming more mainstream around the early to mid ‘00s. Most games made for PS2 were still designed around a 4:3 aspect ratio of course, but gradually more and more started offering built-in widescreen modes as demand grew. There are 3 general ways the PS2 can go about displaying a widescreen picture (or in general really):
Hor+ (Hor Plus) – Extends the horizontal sides of the screen to fill out the screen. Usually the best approach (and almost never used on the real PS2, which is why we need all these widescreen patches)
Vert- (Vert Minus) – Chops off some of the top and bottom sides of the screen while zooming in on the center
Hor+ and Vert- (Hor Plus + Vert Minus) – A bit of both
The vast majority of PS2 games unsurprisingly opt for the ‘worst’ of these 3 options when implementing a widescreen mode, Vert-. In some rare cases you will see the 3rd option (Hor+ and Vert-) used as well. Games like Tekken 5 therefore have a ‘quasi-widescreen’ mode, where you lose parts of the screen at the top and bottom that are considered unimportant to the gameplay but then it zooms in slightly in the center to make it fit within a 16:9 aspect ratio. All Ratchet & Clank and Jak and Daxter games are Vert- as well.
It was of course possible to do a Hor+ widescreen game on a PS2, but the developer had to consider system resources, GS embedded VRAM usage, etc. Zooming/scaling was free on the GS and chopping off some parts of the image prob made sure things still fit within the 4MB GS VRAM, so Vert- was probably the easiest solution. With Hor+ also the horizontal resolution comes into play. The more you extend the horizontal sides of the screen, the higher your horizontal resolution needs to be to still maintain a good picture quality. And the PS2 already relied on the CRT’s ability to make interleaved scanlines look really good to get away with lower than average resolutions.
Below you see Tekken 5’s built-in ‘widescreen’ mode. This is how it would look like on a real PS2 with a widescreen CRT TV. As you can see, this shows all the signs of a Vert- aspect ratio. Parts of the top and bottom are cropped while the image is zoomed in on the center. The two characters appear much larger than they would in 4:3 mode. Widescreen on 6th generation consoles was often an exercise in frustration for the enthusiast. So many games would simply give you Vert- and not really take advantage of the extra screen estate.
Below you will see the ‘correct’ widescreen mode, this is an internal widescreen patch in the LRPS2 core. It corrects the widescreen mode to Hor+. Now more of the game world is being rendered onscreen because the image is extended horizontally, no cropping is being done.
Progressive scan
The PS2 released near the tail end of the CRT TV’s life. HD-ready LCD TVs would not start arriving until 2005 and so TV makers were still trying to push the CRT forward in ways they could. As we have established before, CRT TVs are analog video. To make the move to digital television (DTV) on a CRT, new specifications such as EDTV were necessary. EDTV stood for Enhanced-definition television or Extended Definition Television. Basically, in practice it meant that SDTVs were being made that could support 480p and 576p-line signals in progressive scan. Around 2001, progressive scan-capable CRT TVs started being sold, and games started taking advantage of this.
You needed either a component cable (on NTSC TVs) or RGB SCART cables (Japanese and European TVs) in order to be able to use progressive scan display modes. Composite and RF-AV cables did not support this feature.
By pressing and holding X and Triangle at startup, a progressive scan-supported game would ask the user to choose between normal and progressive scan mode. Progressive scan modes are non-interlaced full frame modes, therefore there would be none of the interlacing artefacts and you’d get full-height backbuffers.
The only disadvantage some of these progressive scan-capable games usually have is that sometimes they reduce the framebuffer depth to 16bpp or lower so that everything can still fit inside the Graphics Synthesizer’s 4MB embedded eDRAM. This is not a general rule but some games do make that tradeoff, so you’re trading no interlacing artefacts for a somewhat less high quality final output image (I.e. more color banding).
On average though, progressive scan would still look better than interlaced mode to most people. Some games like Valkyrie Profile 2 and Gran Turismo 4 would even offer 1080i progressive scan modes. Note that this is a bit deceptive. This mode doesn’t actually make the PS2 output at a full 1920×1080 resolution, it’s just a bit of advanced framebuffer shenanigans to make it ‘look’ higher res than it actually is. For these games, 480p progressive scan mode usually looks better on modern displays.
Let’s for instance analyze Gran Turismo 4’s ‘1080i’ mode. The internal render resolution is actually 640 x 540. The GS’ CRTC then magnifies this to ‘1920×1080’. 640 is ‘magnified’ to 1920 via a Magnification Integer (MAGH) of ‘3’. So 640 * 3 = 1.920. The vertical resolution 540 meanwhile is magnified either by a Magnification Integer (MAGV) of ‘2’ (540 x 2 = 1080), or the interlaced framebuffer switch. So it’s basically a bit of GS CRTC zoom scaling going on. On a CRT this probably looked convincing enough at the time.
Europe and progressive scan (or the lack thereof)
Note that for European versions of the game, progressive scan modes would sometimes be stripped out or removed (God of War 2, Soul Calibur 3). This was probably because of the low adoption rates of progressive scan-capable TVs.
Europe and PAL CRTs (50Hz vs 60Hz)
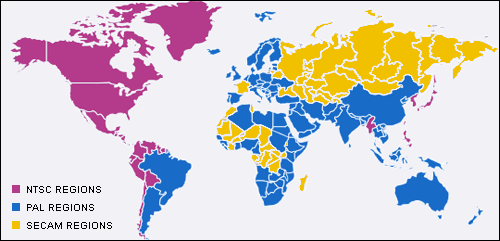
In fact Europeans had plenty of other issues on top. For those that don’t know, in Europe they used PAL signal CRT TVs while in Japan and the United States, NTSC signal CRT TVs were the standard. PAL ran at 50Hz while NTSC ran at 60Hz.
When PS2 launched in Europe, most Dreamcast games already offered the choice between a PAL 50Hz mode and a PAL60 mode. PAL60 (on TVs that supported it) would give a 60Hz image, thereby avoiding the 16.9% reduction in frame rate for many PAL conversions and the additional letterboxes. The added letterboxing was because PAL typically had a higher output resolution than NTSC. However, games most of the time would not bother taking advantage of this as they were either already nearing the ceiling on system resources or simply because they didn’t care about the European/PAL market enough to cater to them.
The situation on PS2 was more complicated. PAL60 was not a real standard so Sony refused to back it. This meant that most PS2 launch games (prob all of them) sadly did not have any 60Hz options, so we were stuck with 50Hz for a while.
Developers that were usually good about providing PAL-optimized games were UK developers like Psygnosis (Wipeout, Destruction Derby), Core Design (Tomb Raider) and Rockstar/DMA Design (Grand Theft Auto). You’d get a 50Hz mode with more scan lines being rendered than the NTSC version. So you’d get better image quality than the NTSC version. However, the game would still run slower because of 50Hz. Some developers would compensate for this by tweaking the game speed, but regardless in general it would almost usually always be worse than the same game being ran at 60Hz.
No PAL60 for PS2, only NTSC for you
Anyway, around 2002 more and more games started having options at startup allowing you to choose between a 50Hz and 60Hz mode, like ICO. How the PS2 dealt with this compared to the Dreamcast was that instead of allowing you to choose between PAL and PAL60 modes, the game would try to switch to NTSC 480i mode instead. Most televisions sold in Europe near the late ’90s actually supported both PAL and NTSC, so this wasn’t much of a compatibility issue. The games that still didn’t offer these PAL/NTSC selectors (like Silent Hill 2 and Metal Gear Solid 2) would put a bit more effort into their PAL conversions and not have the dreaded letterboxing. The 50Hz/60Hz mode was not an easy thing to crack for many developers. Developers like Square would complain about having to ship a 50Hz and 60Hz version of a FMV scene, and because their games were so front loaded with high-quality big FMV scenes, this was not really possible to fit on the DVD. This is the reason why games like Final Fantasy X sticked to 50Hz despite the developer being aware of the growing demand for NTSC 60Hz mode. Eventually the games that would not have these 50Hz/60Hz toggles would become the exception to the rule.
Moving to LCD/HDTVs in the mid ‘00s for the 7th generation
The industry-wide move from CRTs to LCD TVs was a rough one. This happened sometime around 2005 when new consoles were being prepared. The PS2 of course was still around and wouldn’t really die until like late 2007. There were definitely advantages for the upcoming 7th generation consoles, like the PlayStation3 and Xbox 360. Gone were the days of PAL vs. NTSC. Europeans would no longer have to worry if a game would implement a PAL60/60Hz mode. As long as you hook up your HDMI-capable game console to the HDMI-capable display, your game would output at 60Hz. And of course there was the promise of non-interlaced high resolutions by default. Not a lot of people ever had a progressive scan-capable TV, so this would be their first time seeing a 480p or 720p image on a television.
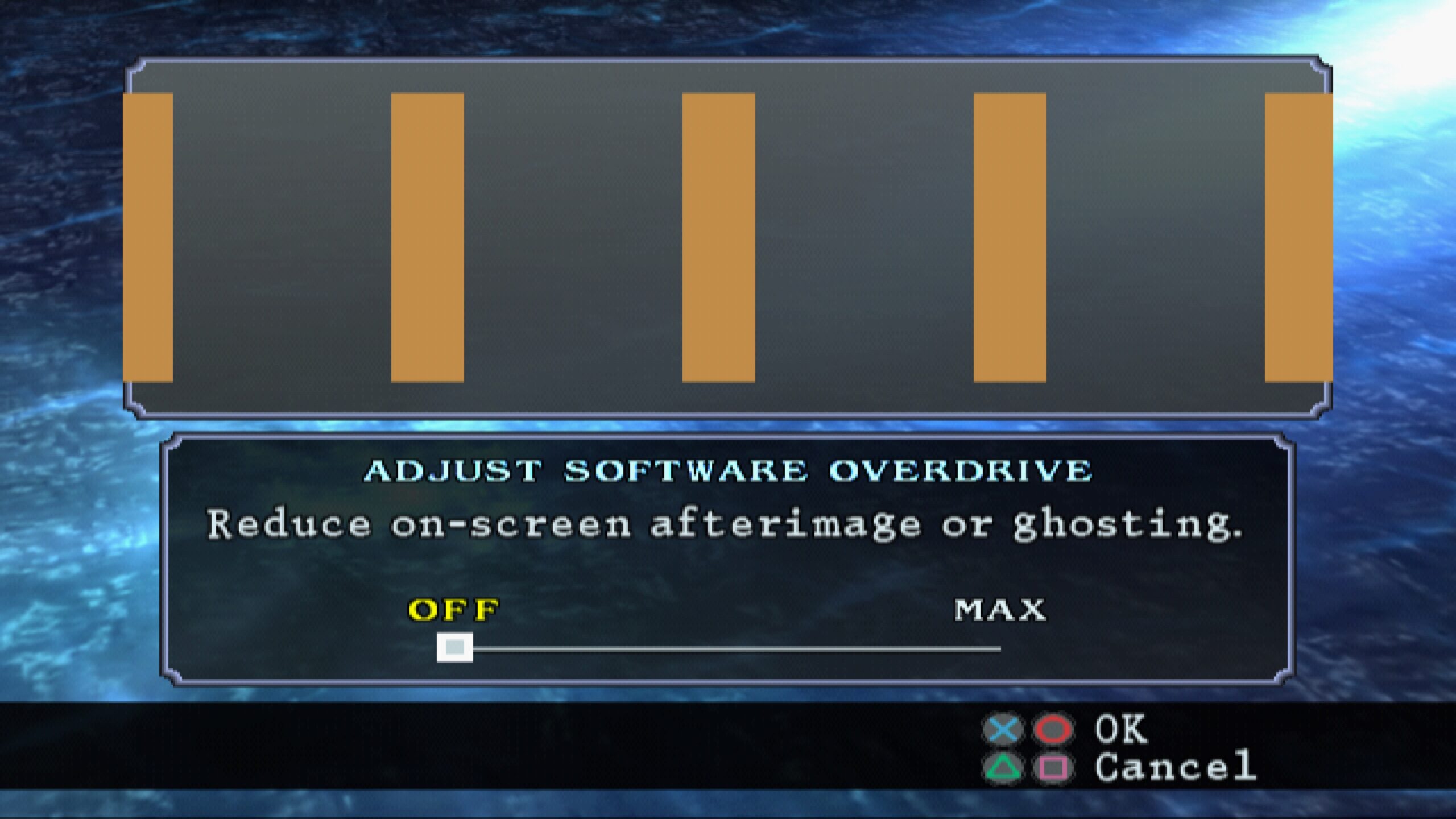
It would take time for people to catch on, but early LCD HD-ready TVs were often of very poor quality with high amounts of latency and ghosting. CRT-based game consoles (such as the PS2) looked especially poor on them. In fact, for the older sixth generation consoles, there were almost no advantages to be had using them on a non-CRT display. Feedback blur (used to great effect in many PlayStation2 games for motion blur effects) would look great on a CRT, but looked disastrous on these early LCD screens with the heavy ghosting they were known for. Some games like Soul Calibur 3 would have an in game setting (Software Overdrive) that would try to reduce the afterimage effects on LCD screens.
There was no fixing the latency though or the lack of motion clarity, and this problem would persist for decades. Motion clarity in fact is only now finally being addressed on modern displays for these consoles with the arrival of BlurBusters’ ‘CRT beam racing simulator’ (see our article here for more details). On a modern OLED screen in 202x we can finally enjoy near CRT-like latency with the motion clarity of a CRT (CRT beam simulator shader) AND the looks of a CRT (any advanced CRT shader).
Remember that this project exists for the benefit of our users, and that we wouldn’t keep doing this were it not for spreading the love to our users. This project exists because of your support and belief in us to keep going doing great things. We have always prioritized the endusers experience, and unlike others, we have never emburdened them with in-app ads, monetization SDKs or paywalled features, and we intend to continue to do so. If you’d like to show your support, consider donating to us. Check here in order to learn more. In addition to being able to support us on Patreon, there is now also the option to sponsor us on Github Sponsors! You can also help us out by buying some of our merch on our Teespring store!
Remember that this project exists for the benefit of our users, and that we wouldn’t keep doing this were it not for spreading the love to our users. This project exists because of your support and belief in us to keep going doing great things. We have always prioritized the endusers experience, and unlike others, we have never emburdened them with in-app ads, monetization SDKs or paywalled features, and we intend to continue to do so. If you’d like to show your support, consider donating to us. Check here in order to learn more. In addition to being able to support us on Patreon, there is now also the option to sponsor us on Github Sponsors! You can also help us out by buying some of our merch on our Teespring store!
Changelog
We never got to release 1.18.0 so we’re moving straight to 1.18.0. Therefore we include all the changes for 1.18.0 as well.
1.19.0
AI: Revert AI translation to previous version (fix for translation not working with HW rendered cores)
APPLE: Try to use system preferred language
APPLE: Correctly register for filetypes uniquely
APPLE/MFI: improved Switch Online controller support through MFi
AUDIO: Bring back audio toggling on menu toggle
CHEEVOS: Build a default RetroAchievements memory map when no RetroAchievements game is loaded
CHEEVOS: Update to rcheevos 11.3
CHEEVOS: fix hardcore acting as if it’s enabled when it isn’t
CLOUDSYNC/LINUX: Enable Cloud Sync by default on Linux builds with network (#16456)
CLOUDSYNC/WEBOS: Enable Cloud Sync by default on Linux builds with network (#16456)
CORE: Set compute fps stats logging to debug level
EMSCRIPTEN: Added M2000 to core selection dropdown
FFMPEG: Add compatibility with FFMPEG 7.0
GLSLANG: Remove unneeded ENABLE_HLSL code from glslang
GENERAL: Memory leak: Dynamic allocation from msg_hash_get_help_us_enum was not freed.
INPUT/KEYBOARD: Add support for multimedia keys – Extended RETROK_ values with 18 new items, commonly found on “multimedia” keyboards. Mapping added for SDL, X11, Wayland, dinput, winraw keymaps.
INPUT/MFI: Pressure sensitive left/right triggers
INPUT/MFI: Fix Start + L1/L2/R2 combinations
INPUT/MFI: Support strong and weak rumble
INTL: Fetch translations from Crowdin
INTL: Add Galician and Norwegian to list of languages
LAKKA: Display reboot/shutdown message also when not saving config on exit
LAKKA: Provide update URL and target name at buildtime
LIBRETRO: Add a debug message for the SET_ROTATION callback
macOS: Default Accessibility on if VoiceOver is on
iOS: default audio sync on again, also more mfi logging
iOS: Fix Import Content
iOS: Fix ios-arm64 nightly build crash
iOS: Import content from iCloud
iOS: Fix #16485 crash on startup
iOS: Display app icon in app icon picker in materialui
iOS/tvOS: Various QoL improvements
iOS/tvOS: Fix a couple more path name mangling bugs
iOS/tvOS: Better way of packaging Frameworks
iOS/tvOS: define PACKAGE_VERSION to be App Store MARKETING_VERSION
iOS/tvOS: Fix keyboard handling for app store builds
iOS/tvOS: Fix escaping the sandbox for jailbroken devices
iOS/tvOS: default accessibility on if voice over is enabled
iOS/tvOS: better way of reporting available memory
macOS/iOS/tvOS: enable text-to-speech using AVSpeechSynthesizer.
tvOS: Fix scaling for 720p
MENU: New function in Quick Menu: Add to Playlist
MENU/XMB: New theme: FlatUX, designed to merge FlatUI and Retroactive themes into a single, unified design
NETWORKING/RETROPAD CORE: Fix socket close method
PIXMAN: Update pixman-private.h – patch to fix build issue with musl
PLAYLIST: Cleanup ‘Add to Playlist’ (#16495)
SCANNING: Fix for scanning PSP ISOs (and probably few others)
SAVES: Fix core config saving
SAVES: Fix save new config name when core loaded
SAVESTATES: Increase save state chunk size for all platforms – Even a class 6 or class 10 SD card can handle reads and writes on the order of MB/s, which means a 4KB chunk size is just wasting time in syscalls. This could maybe be fixed with a buffering reader but I don’t feel comfortable tweaking libretro-common’s VFS to handle that. Instead, I thought it would be good to both remove an ifdef and increase the chunk size to 128KB. For cores with small states this will should make state saving virtually instantaneous, and for cores with large states it should be a 32x speedup.
VIDEO: Fix crash when using threaded video – for Mesa 23.2 and later
VIDEO/GL: Fix reinitialization of the threaded gl drivers
VIDEO/VULKAN: Add support for A2R10G10B10 HDR format
VIDEO/VULKAN: Implement HDR readback – screenshot support
WAYLAND: Ignore configure events during splash (fix not remembering window size)
WAYLAND: Use frontend signal handler to quit (fix quit by window close)
WAYLAND: Commit viewport resizes (window resize is more responsive)
UWP: Align MESA to alpha-2-resfix – Remove wrong resolution special handling for OPENGL
UWP: 4K fix: align MESA reading of ClientRect to retroarch procedure, this fixes max resolution being set to 1080p. As reading must be done inside an UI thread and is in fact an async operation which might delay frame generation, the reading itself is doen once and cached, give that changing resolution while the app is running is an unlikely corner-case use
WINDOWS: Windows mouse ungrab must release the mouse instead of confine it to the current desktop (#16488)
WINDOWS: Fix numlock/pause key release events
1.18.0
AI: Fix narrator language when AI translation and menu languages are different
DISK CONTROL: Add option to disable initial disk change
DISK CONTROL: Visibility option for disk control notifications
DRM: Fix mode vrefresh calculation. When using an interlaced/doublescan mode, the vertical refresh rate is mis-calculated.
EMSCRIPTEN: Fix mouse Y parameter translation in rwebinput
INPUT: Fix input state combos including R3 and false triggers of RETROK_UNKNOWN
INPUT: Add a new turbo mode, “Classic (Toggle)”
INPUT: Fix bind hold when axis does not rest at 0
INPUT: Limit axis threshold setting to sensible values
INPUT: Add Overlay Mouse, Lightgun, and Pointer
INPUT/ANDROID: Fix mouse grab behavior on Android
INPUT/LINUXRAW: Fix device name and hotplug reconnect
IOS: Minor iOS JIT availability information
IOS/TVOS: Pause application on applicationWillResignActive
LIBRETRO: Add Doxygen-styled comments to parts of the libretro API
LUA: Update Lua to version 5.3.6
MENU: Add sublabels for input bind common entries
MENU: Don’t load history and favorites if size is 0
MENU: Don’t disable fast forward when entering menu
MENU: Reorder and reduce depth of User Interface menu
MENU/OZONE: Fix sidebar wraparound, visibility after config load, crash after playlist delete
MENU/OZONE: Fix sidebar and sublabel animations
OSX/MACOS: Fix crash on non-Metal build
OSX/MACOS: Add portable.txt as flag for portable install
REMOTE RETROPAD: add display for analog axes, indication of inputs already pressed
SAVES: Allow combining saves in content dir with save sorting
SHADER: Added rolling scan line simulation based on the shader subframe feature. This is implemented with a scrolling scissor rect rather than in the shader itself as this is more efficient although may not work for every shader pass – we may need an option to exclude certain passes. The implementation simply divides the screen up by the number of sub frames and then moves the scissor rect down over the screen over the number of sub frames
TVOS: Force asset re-extraction when cache is deleted
TVOS: Add history and favorites to Top Shelf
TVOS: Fix crash when history item does not have a label
UWP: Enable HAVE_ACCESSIBILITY for UWP builds
UWP: Allow UWP build to work with a modified version of Mesa Gallium D3D12
VIDEO: Add subframe shader support for Vulkan/GLcore/DX10-11-12, enabling shaders to run at higher framerate than the content
VIDEO: Fix restoring fullscreen/windowed setting when unloading override
VIDEO/VULKAN: Fix HDR with Vulkan after reinit
VIDEO/VULKAN: Remove the use of oldSwapchain
VIDEO/GL2: Fix OpenGL ES version detection
WEBDAV: Fixed SEGFAULT in WebDav task sync + type changes
WEBOS: Fix build, add core location on webosbrew.org
WIN32: Fix Alt+Enter not working when menubar is disabled
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Contains information related to marketing campaigns of the user. These are shared with Google AdWords / Google Ads when the Google Ads and Google Analytics accounts are linked together.
90 days
__utma
ID used to identify users and sessions
2 years after last activity
__utmt
Used to monitor number of Google Analytics server requests
10 minutes
__utmb
Used to distinguish new sessions and visits. This cookie is set when the GA.js javascript library is loaded and there is no existing __utmb cookie. The cookie is updated every time data is sent to the Google Analytics server.
30 minutes after last activity
__utmc
Used only with old Urchin versions of Google Analytics and not with GA.js. Was used to distinguish between new sessions and visits at the end of a session.
End of session (browser)
__utmz
Contains information about the traffic source or campaign that directed user to the website. The cookie is set when the GA.js javascript is loaded and updated when data is sent to the Google Anaytics server
6 months after last activity
__utmv
Contains custom information set by the web developer via the _setCustomVar method in Google Analytics. This cookie is updated every time new data is sent to the Google Analytics server.
2 years after last activity
__utmx
Used to determine whether a user is included in an A / B or Multivariate test.
18 months
_ga
ID used to identify users
2 years
_gali
Used by Google Analytics to determine which links on a page are being clicked
30 seconds
_ga_
ID used to identify users
2 years
_gid
ID used to identify users for 24 hours after last activity
24 hours
_gat
Used to monitor number of Google Analytics server requests when using Google Tag Manager
1 minute
Marketing cookies are used to follow visitors to websites. The intention is to show ads that are relevant and engaging to the individual user.
A video-sharing platform for users to upload, view, and share videos across various genres and topics.
Registers a unique ID on mobile devices to enable tracking based on geographical GPS location.
1 day
VISITOR_INFO1_LIVE
Tries to estimate the users' bandwidth on pages with integrated YouTube videos. Also used for marketing
179 days
PREF
This cookie stores your preferences and other information, in particular preferred language, how many search results you wish to be shown on your page, and whether or not you wish to have Google’s SafeSearch filter turned on.
10 years from set/ update
YSC
Registers a unique ID to keep statistics of what videos from YouTube the user has seen.
Session
DEVICE_INFO
Used to detect if the visitor has accepted the marketing category in the cookie banner. This cookie is necessary for GDPR-compliance of the website.
179 days
LOGIN_INFO
This cookie is used to play YouTube videos embedded on the website.
2 years
VISITOR_PRIVACY_METADATA
Youtube visitor privacy metadata cookie
180 days
You can find more information in our Cookie Policy and .