
Since the paraLLEl-RDP rewrite was unleashed upon the world, a fair bit of work has gone into it. Mostly performance related and working around various drivers.
Rendering bug fixes
Unsurprisingly, some bugs were found, but very few compared to what I expected. All the rendering bugs were fortunately rather trivial in nature, and didn’t take much effort to debug. I can only count 3 actual bugs. To be a genuine bug, the issue must be isolated to paraLLEl-RDP. Core bugs are unfortunately quite common and a lot of core bugs were mistaken as RDP ones.
Mega Man 64 – LODFrac in Cycle 1

The RDP combiner can take the LOD fractional value as inputs to the combiner. However, the initial implementation only considered that Cycle 0 would observe a valid LODFrac value. This game however, uses LODFrac in Cycle 1, and that case was completely ignored. Fixing the bug was as simple as consider that case as well, and the RDP dump validated bit-exact against Angrylion. I believe this also fixed some weird glitching in Star Wars – Naboo. At least it too passed bit-exact after this fix was in place.
Mario Tennis crashes – LoadTile overflow
Some games, Mario Tennis in particular will occasionally attempt to upload textures with broken coordinates. This is supposed to overflow in a clean way, but I missed this case, and triggered an “infinite” loop with 4 billion texels being updated. Needless to say, this triggered GPU crashes as I would exhaust VRAM while spamming an “infinite” loop with memory allocations. Fairly simple fix once I reproduced it. I believe I saw these crashes in a few other games as well, and it’s probably the same issue. Haven’t seen any issues since the fix.
Perfect Dark logo transition
Not really an RDP rendering issue, but VI shenanigans. This was a good old case of a workaround for another game causing issues. When the VI is fed garbage input, we should render black, but that causes insane flickering in San Francisco Rush, since it strobes invalid state every frame. Not entirely sure what’s going on here (not impossible it’s a core bug …), but I applied another workaround on top of the workaround. I don’t like this 🙁 At least the default path in the VI implementation is to do the expected thing of rendering black here, and parallel-n64 opts into using weird workarounds for invalid VI state.
Core bugs
Right now, the old parallel-n64 Mupen core is kind of the weakest link, and almost all issues people report as RDP bugs are just core bugs. I’ll need to integrate this in a newer Mupen core and see how that works out.
Improving compatibility with more Vulkan drivers
As mentioned in my last post, a workaround for lack of VK_EXT_external_memory_host was needed, and I implemented a fairly complex scheme to deal with this in a way that is not horribly slow. Effectively, we now need to shuffle memory back and forth between two views of RDRAM, the CPU-owned RDRAM, and GPU-owned RDRAM. The implementation is quite accurate, and tracks writes on a per-byte basis.
The main unit of work submitted to the GPU is a “render pass” (similar in concept to a Vulkan render pass). This is a chunk of primitives which all render to the same addresses in RDRAM and which do not have any feedback effect, where texture data is sampled from the frame buffer region being rendered to. A render pass will have a bunch of reads from RDRAM at the start of the render pass, where frame buffer data is read, along with all relevant updates to TMEM. All chunks of RDRAM which might be read, will be copied over to GPU RDRAM before rendering. We also have a bunch of potential writes after the render pass. These writes must eventually make their way back to CPU RDRAM. Until we drain the GPU for work completely, any write made by the RDP “wins” over any writes made by the CPU. During the “read” phase of the render pass, we can selectively copy bytes based on the pending writemask we maintain on the GPU. If there are no pending writes by GPU, we optimize to a straight copy.
As for performance, I get around 10-15% FPS hit on NVIDIA with this workaround. Noticeable, but not crippling.
Android
Android SoCs do not always support cache-coherency with the GPU, so that’s added complexity. We have to carefully flush caches and invalidate caches on CPU side after we write to GPU RDRAM and before we read from it respectively. I also fixed a bunch of issues with cache management in paraLLEl-RDP which would never happen on a desktop system, since everything is essentially cache coherent.
With these fixes, paraLLEl-RDP runs correctly on at least Galaxy S9/S10 with Android 10 and Mali GPUs, and the Tegra in Shield TV. However, the support for 8/16-bit storage is still very sparse on Android, and I couldn’t find a single Snapdragon/Adreno GPU supporting it, oh well. One day Android will catch up. Don’t expect any magic for the time being w.r.t. performance, there are some horrible performance issues left which are Android specific outside the control of paraLLEl-RDP, and need to be investigated separately.
Fixing various performance issues
The major bulk of the work was fixing some performance issues which would come up in some situations.
Building a profiler
To drill down into these issues, I needed better tooling to be able to correlate CPU and GPU activity. This was a good excuse to add such support into Granite, which is paraLLEl-RDP’s rendering backend, Beetle HW Vulkan’s backend, and the foundation of my personal Vulkan rendering engine. Google Chrome actually has a built-in profile UI frontend in chrome://tracing which is excellent for ad-hoc use cases such as this. Just dump out some simple JSON and off you go.
To make a simple CPU <-> GPU profiler all you need is Vulkan timestamp queries and VK_EXT_calibrated_timestamps to improve accuracy of CPU <-> GPU timestamp correlation. I made use of the “pid” feature of the trace format to show the different frame contexts overlapping each other in execution.
Anyone can make these traces now by setting environment variables: PARALLEL_RDP_BENCH=1 GRANITE_TIMESTAMP_TRACE=mytrace.json, then load the JSON in chrome://tracing.
Why is Intel Mesa much slower than Intel Windows?
This was one of the major questions I had, and I figured out why using this new tool. In async mode, performance just wouldn’t improve over sync mode at all. The reason for this is that swap buffers in RetroArch would completely stall the GPU before completing (“refresh” in the trace). I filed a Mesa bug for this. I’ll need to find a workaround for this in RetroArch. With a hacky local workaround, iGPU finally gives a significant uplift over just using the CPU in this case. Trace captured on my UHD 620 ultrabook which shows buggy driver behavior. Stalling 6 ms in the main emulation thread is not fun. 🙁
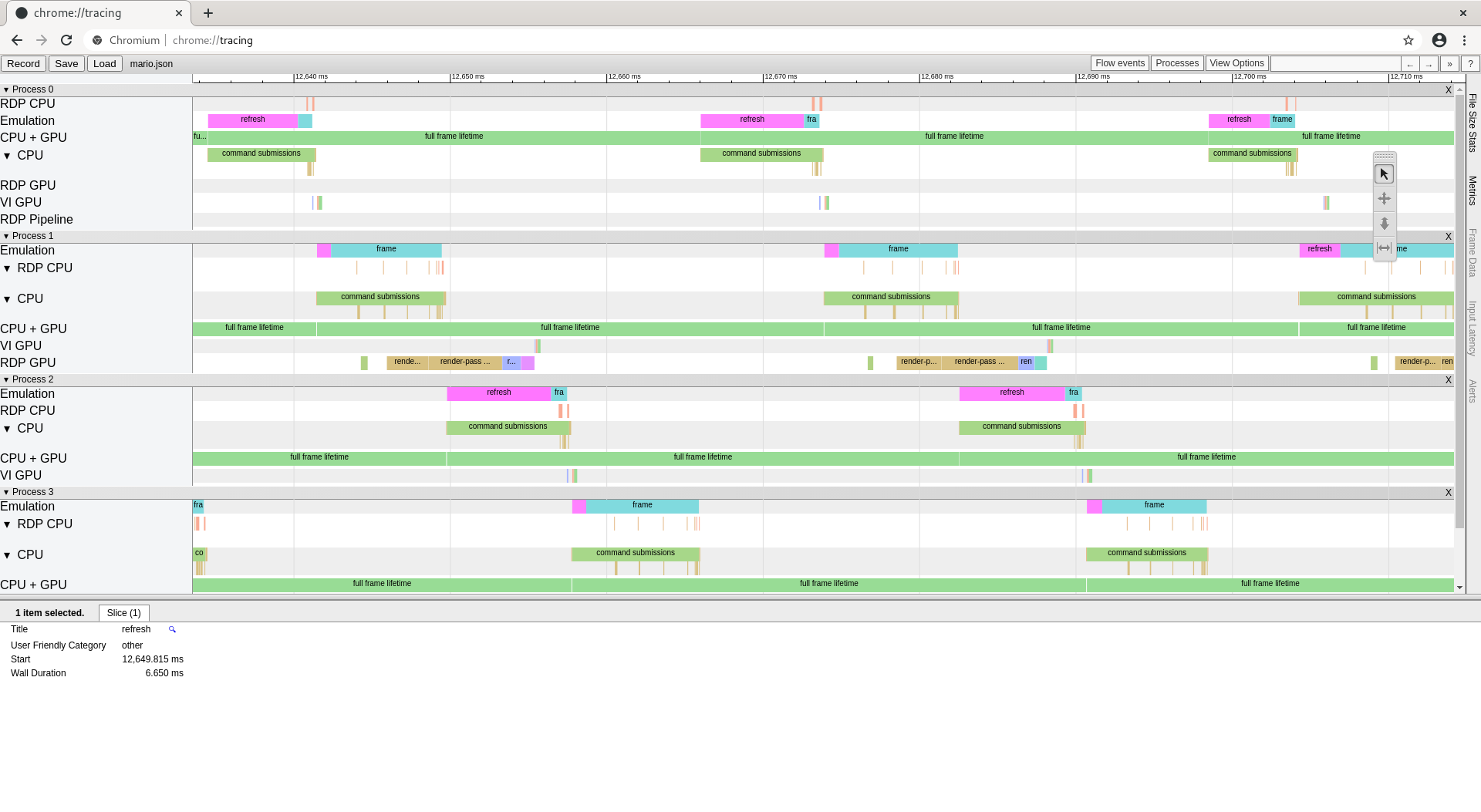
Fixing full GPU stalls, or, why isn’t Async mode improving performance?
This was actually a parallel-n64 bug again. To manage CPU <-> GPU overlap, the Vulkan backend uses multiple frame contexts, where one frame on screen should correspond with one frame context. The RDP integration was notified too often that a frame was starting, and thus would wait for GPU work to complete far too early. This would essentially turn Async mode into Sync mode in many cases. Overall, fixing this gained ~10-15% FPS on my desktop systems.
Be smarter about how we batch up work for the GPU – fixing stutters in Mario Tennis
Mario Tennis is pretty crazy in how it renders some of its effects. The hazy effect is implemented with ~50 (!) render passes back to back each just rendering one primitive. This was a pathological case in the implementation that ran horribly.

The original design of paraLLEl-RDP was for larger render passes to be batched up with a sweet spot of around 1k primitives in one go, and each render pass would correspond to one vkQueueSubmit. This assumption fell flat in this case. To fix this I rewrote the entire submission logic to try to make more balanced submits to the GPU. Not too large, and not too small. Tiny render passes back-to-back will now be batched together into one command buffer, and large render passes will be split up. The goal is to submit a meaningful chunk of work to the GPU as early as possible, and not hoard tons of work while the GPU twiddles its thumbs. This is critically important for Sync mode I found, because once we hit a final SyncFull opcode, we will need to wait for the GPU to complete all pending work. If we have already submitted most of the relevant work, we won’t have to wait as long. Overall, this completely removed the performance issue in Mario Tennis for me, and overall performance improved by a fair bit. > 400 VI/s isn’t uncommon in various games now on my main system. RDP overhead in sync mode usually accounts for 0.1 ms – 0.2 ms per frame or something like that, quite insignificant.
Performance work left?
I think paraLLEl-RDP itself is in a very solid place performance-wise now, the main issues are drilling down various WSI issues that plague Intel iGPU and Android, which I believe is where we lose most of the performance now. That work would have to go into RetroArch itself, as that’s where we handle such things.
Overall, remember that accurate LLE rendering is extremely taxing compared to HLE rendering pixel-for-pixel. The amount of work that needs to happen for a single pixel is ridiculous when bit-exactness is the goal. However, shaving away stupid, unnecessary overhead has a lot of potential for performance uplift.